Tailoring Intelligence: Adapting AI Models for Enhanced Performance — Fine tuning, alignment and model merging (Part 1)
Summary:
- Fine-tuning is a powerful technique for adapting pre-trained models to specific tasks and domains, enabling better performance, cost optimization, and customization. Just as a skilled tailor adjusts a suit to perfectly fit the wearer, fine-tuning allows to adapt AI models to excel at specific tasks and domains.
- Fine-tuning and Retrieval-Augmented Generation (RAG) serve complementary roles. Fine-tuning optimizes models for specific tasks but has limited ability to integrate new knowledge.
- Fine-tuning smaller, task-specific open-source models with appropriate data can lead to equal or superior performance compared to using a larger, more general model, and at a fraction of the cost for specific tasks.
- The fine-tuning process involves critical decisions around data selection, computational resources, training approach, and evaluation. Navigating the tradeoffs requires carefully considering the task, budget, and desired outcomes.
- Fine-tuning will be essential for developing AI agents that can understand and interact with complex systems, adapt to user needs, and provide personalized, context-aware interactions. The use of multiple smaller fine-tuned models in parallel can also lead to economically feasible agents that perform reliably on specific tasks.
- Fine-tuning offers businesses a competitive advantage by enabling them to create proprietary AI models tailored to their unique requirements, brand voice, tone, and style.
- We are still very early in the adoption curve; most companies are in the process of setting up their RAG pipelines, and few have fine-tuned a model. However we anticipate a surge in companies that fine-tune models in the coming years.
Introduction to fine-tuning
Following the release of GPT-3.5 last year, many companies began integrating generative AI capabilities into their products and operational processes. Initially, these organizations predominantly adopted closed sourced pre-trained models, notably GPT-3.5, for its ease of integration, robust performance, and advanced out-of-the-box capabilities. However, the emergence of competitive open-source models like Llama 1 & 2 and Mixtral 7B led to a diversification in the use of models. Despite the great general performance of these models, trained on extensive and varied datasets, they often fall short in addressing company-specific needs.
In a previous article, we explored Retrieval-Augmented Generation (RAG) and its role in enhancing the accuracy and reliability of generative AI models by incorporating knowledge from external sources. However, it’s crucial to acknowledge that RAG is not a universal solution for all challenges. Effective strategies to complement RAG include fine-tuning, in which a general-purpose model is customized for specific tasks or domains by further training it on a more targeted dataset. Just as a skilled tailor adjusts a suit to perfectly fit the wearer, fine-tuning allows us to adapt AI models to excel at specific tasks and domains. By carefully selecting data, choosing the right pre-trained model, and adjusting hyperparameters, we can create a custom-fitted AI solution that meets the unique needs of each business. If done correctly, these processes can lead to better performance than the base model. For example, PI 2.5 from Inflection AI undergoes fine-tuning to achieve its signature empathetic style.
Fine-tuning is the process of adapting a pre-trained model to a task by carefully adjusting its weights to better capture the nuances of the new supervised dataset. Fine-tuning is a highly effective approach for enhancing model performance, especially when customizing for a specific task. This method is particularly beneficial for adjusting output style, tone (formal, serious, empathetic), output lengths, or incorporating task-specific industry vocabularies. Given that you are specializing the model for your task, it makes them, in a way, more deterministic so that they output answers in your desired style compared to a base models. Beyond the focus on model specialization, fine-tuning also offers significant cost optimization advantages. By improving performance, it can reduce the need for extensive prompt engineering and the number of tokens required for prompts.
Many people mistakenly believe that fine-tuning a language model is the primary way to introduce new knowledge. While fine-tuning on a dataset containing information not well represented in the original pre-training data can expose the model to novel facts and associations, or introduce company-specific knowledge about a topic on which it was already trained, it primarily optimizes the model’s ability to apply its existing knowledge rather than dramatically expanding it. For introducing external knowledge, techniques like RAG are more suitable. Additionally, for directly incorporating knowledge within a model, the emerging field of model merging offers a potentially more efficient alternative to training large models from scratch (Arcee a proud Flybridge portfolio company is a pioneer in this field).
Navigating the process, decisions and challenges
While fine-tuning offers a powerful way to adapt models for specific tasks, it’s crucial to be aware of its limitations. These limitations include the need for substantial investment in data gathering and preparation, the required computational GPU cost and overhead of managing hardware clusters, and the potential for introducing harmful, biased, or unwanted content through the fine-tuning dataset. Additionally, fine-tuning processes can lack stability, leading to risks of overfitting or catastrophic forgetting. Finally, and importantly, there is no guarantee of success after the process; for instance, if the data inputs are not of high quality, it can even degrade model performance.
Similar to RAG, there are many decisions that founders and operators must make when fine-tuning a model, and it is critical to acknowledge those decisions and possible trade-offs. Below is an overview of the key steps involved in the fine-tuning process. As a complement to these insights, in 2024 Peter Schmit from Hugging Face published a thorough guide on how to effectively fine-tune LLMs. Weights and Biases also did a very detailed three part series on How to fine tune a model (Part 1, Part 2, Part 3), and AI Markerspace also has a live tutorial in fine-tuning a model.
(1) Defining the Task and Evaluating the Need for Fine-Tuning: Begin by precisely identifying the task or problem you aim to address. It is crucial to assess whether fine-tuning a model is the most effective strategy for your specific needs. Before embarking on the fine-tuning process, consider alternative approaches such as prompt engineering, testing few-shot learning, and RAG. These methods can offer simpler and quicker solutions that might sufficiently meet your requirements without fine-tuning and the related upfront cost.
- It’s important to weigh the costs and benefits of fine-tuning. For instance, fine-tuning involves upfront GPU usage. Evaluate if the potential savings gained from reducing prompt lengths or improving task efficiency justify the costs. This is particularly relevant for infrequent tasks, where fine-tuning costs could surpass the benefits over time. Ritesh from Cerebras recently shared an interesting article delving into the cost/accuracy comparison of prompt engineering, RAG, pre-train, and fine-tuning, understanding, as previously stated, that several of them can be used at the same time and often complement each other.
- It has been shown that the narrower and more specific the task, the greater the benefit and performance of fine-tuned models compared to baseline models.
- The worst thing a founder or executive can do is fine-tune for the sake of fine-tuning and just expect the output to improve without having a clear understanding of what they want to achieve through the process.
(2) Selecting the pre-trained model to fine tune and assessing Computational Resources and Budget: The choice involves weighing the trade-offs between model size and resource demands. When choosing a pre-trained model to fine-tune, carefully evaluate your computational resources and budget. Larger models can capture more complex patterns, and generalize better but require more data and computational power to train. In contrast, smaller models are more economical,but may not perform as well or generalize effectively. Aim to strike a balance between performance goals and budgetary limits, selecting a model that satisfies both technical needs and resource constraints.
- It is important to use the base pre-trained model that best fits the specific task, as some models may perform better on general benchmarks, but smaller more efficient models may perform equally or better for a particular task.
- Depending on the model selection and the amount of data processed, fine-tuning can cost between $100 and $50k in most cases and require 1 to 100s of GPUs.
- Another critical aspect is deciding between open-source and closed-source models. Open-source models offer cost-effectiveness, community support, higher ownership levels, control, and transparency. However, despite significant advancements, open-source models may still underperform compared to models like GPT-4 or Claude3 on most tasks. Additionally, open-source models often lack formal support structures (though they benefit from community input). Closed-source models, on the other hand, provide professional support, customization options. They also offer enhanced security for sensitive applications, though this comes at a higher cost and with reduced ownership and transparency.
(3) Data Selection, Preparation, and Preprocessing: The cornerstone of any fine-tuning process is the data you use: as the adage goes, “garbage in, garbage out.” It is crucial to have high-quality datasets that relate to your specific task. Although fine-tuning requires much less data, perhaps 10k to 100k instruction-QA pairs compared to the trillions of tokens of pre-training, you still need a significant amount of data, which may not be possible for early-stage companies. If this is the case, anticipating fine-tuning in the future can be an important part of the overall application design for an early product such that robust, quality data is collected quickly as application usage increases.
- Regarding what data to use, people have several options, including utilizing open-source datasets (e.g Orca math dataset), proprietary datasets, creating synthetic data, leveraging internal data sources, or employing a combination of these methods. It’s critical to compile a dataset that is relevant and tailored to your specific task. The selection process involves navigating trade-offs among data quality, cost, and time. In the GenAI context, there is significant debate and research on the benefits of using synthetic data to fine-tune and pre-train models. From the experts I spoke with, there is consensus, even from those who are bullish on synthetic data, that actual data for the particular task you want to fine-tune for will lead to better outcomes. Whether it is worth it depends on how much data the company already has, how easily it can process it, and whether the delta in improvement is worth the effort compared to generating synthetic data.
- Fine-tuning with irrelevant or low-quality data can introduce errors into a model’s learned patterns. This leads to inaccurate or fabricated outputs, potentially leading to worse performance than the original base model.
- To ensure optimal model performance, construct a dataset that accurately mirrors your target task or domain. This dataset should encompass the diversity and nuances of the language to aid the model in generalizing well and handling varied inputs effectively. Incorporate variations in format, keywords, and context that could manifest in real-world data. For highly specialized tasks, less data is often sufficient. While ongoing research explores the optimal amount of data, this varies depending on the task and your fine-tuning approach (full fine-tuning vs. parameter-efficient methods).
- Can use model’s that help to convert unannotated text into task-specific training datasets for fine tuning like with Bonito.
- Data integration and cleaning can be a significant undertaking. Real-world data is often messy, containing missing values, inconsistent formats, and errors. You’ll also need to convert the data into a format suitable for fine-tuning, such as generating question-answer pairs, formatting it in the correct instruction, input, and output format, adding the End of String Token, and finally tokenizing the dataset. LLMs can streamline this process, saving considerable time and money.
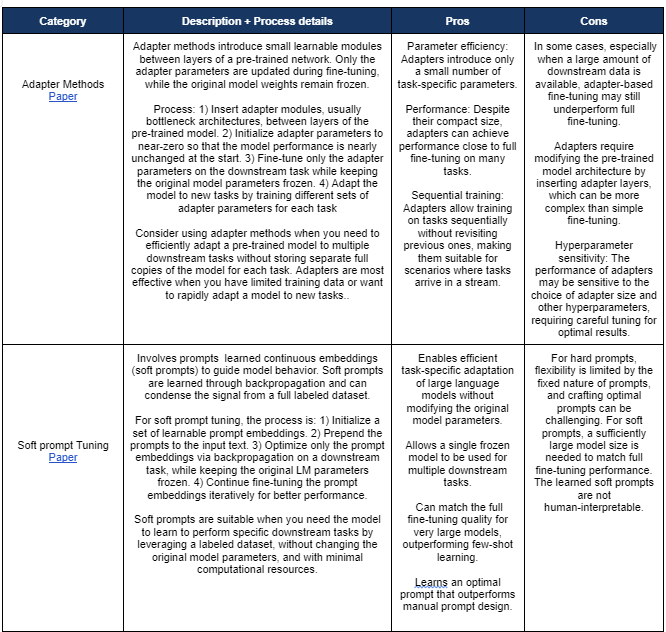
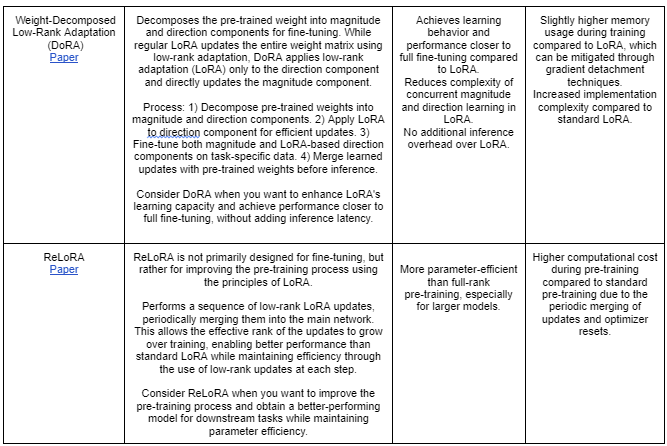
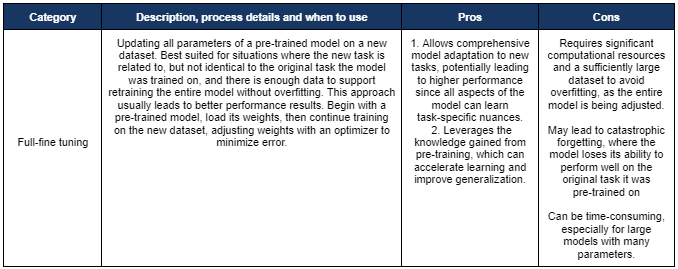
(4) Defining the Fine-Tuning Approach: fine-tuning choices range from full model fine-tuning to parameter-efficient methods. Each approach offers distinct advantages and limitations, making it important to select the one that best suits your scenario and use case. Refer to Appendix A for a detailed comparison of these fine-tuning techniques, including descriptions, pros, and cons. People should understand the strengths and weaknesses of each method, and how they align with their specific needs
- Current literature generally favors parameter-efficient methods as a highly effective way to fine-tune language models, especially when leveraging techniques like LORA and QLORA. Use LoRA when you need to efficiently fine-tune a model across various tasks with limited computational resources, and when a slight performance trade-off is acceptable. Examples of such applications include domain-specific chatbots, sentiment analysis, named entity recognition (NER), and text summarization. The core principle of LORA is that you can significantly alter a neural network’s behavior by modifying only a small subset of its parameters, eliminating the need for full network retraining. This process involves introducing new, task-specific parameters into the model. These parameters are far fewer in number than the original model’s parameters, leading to quicker adjustment and optimization. In practice, this is often achieved through techniques such as adding adapter layers or employing low-rank matrix factorization — hence the name ‘Low-Rank Adaptation’ (LORA).
- Refer to this source by Sebastian Raschka for practical tips for fine-tuning LLMs suing LORA
(5) Setting Up the Training Environment, Training, Monitoring, Experimenting and Adjusting: Configuring the training environment involves carefully selecting and tuning hyperparameters, which are critical for guiding the fine-tuning process. Pay close attention to the learning rate (which controls how much the model’s weights update in response to errors), as this is crucial for both the speed and effectiveness of the training. Other important considerations include batch size (the number of samples the model processes before updating its weights, affecting training speed, memory usage, and generalization), epochs (the number of times the model sees the entire training dataset), and optimizer-specific settings (such as Adam or RMSprop).
- Start with common default values for your chosen model. Experiment by adjusting and monitoring training progress with metrics like loss and accuracy. Consider experimenting with different hyperparameters, including learning rate, batch size, and model architecture. To streamline the process, utilize automated tools like grid search, random search, or Bayesian optimization. These tools can help you identify the best hyperparameter settings — including optimizer choice (Adam, SGD, etc.), learning rate, and other related parameters — to optimize your model’s training.
- Although experimentation is great, if budget is a constraint, try to leverage commonly used settings.
- To Kickstart the training process with your curated dataset, keep a close eye on the validation loss to detect early signs of overfitting. Depending on the complexity of the task and the dataset size, consider gradually unfreezing additional layers, allowing the model to adapt to the new task incrementally.
- Regular or Gradient checkpointing is key for tracking progress and ensuring that training can resume without data loss in case of interruptions.
- Implementing early stopping strategies can prevent overfitting by terminating training if the validation loss starts deteriorating.
- Hugging face transformers library is a popular option that enables to fine-tune the latest Open Source LLMs on your dataset. They also have the TRL for fine-tuning instruction models.
(6) Evaluating Model Performance and Making Adjustments: After the initial fine-tuning process, it’s crucial to evaluate the model’s performance to determine its readiness for the intended task. Employ a combination of A/B testing (e.g., letting GPT-4 select the best answer between fine-tune model and base model), human evaluations, and benchmark metrics — such as accuracy, precision, recall, F1 score, BLEU, and ROUGE scores. These methods offer both qualitative and quantitative insights, allowing for a comprehensive assessment. Based on your evaluation results, you may need to revisit previous steps, such as data selection and preparation, or adjust training parameters. Strategies like data augmentation, hyperparameter tuning, or extending the training period could be necessary to achieve the desired performance.
- Ealry in the process you should have a defined dataset that you will use to evaluate performance after the fine-tuning process.
- General benchmarks offer great insight into model performance, but you should focus on tests that evaluate the performance for your particular task.
- Doing good evaluations is hard (Patronus AI has an excellent article that dives deeper into these challenges)
- Although there are good valuation metrics, different from traditional classifier tasks, the output of generative AI models is highly subjective to personal needs. This makes evaluation more difficult and remains a current challenge to solve.
(7) Save and deploy: Save the optimized model and deploy it in a production environment.
(8) Rinse and Repeat: as more, relevant, data becomes available etc - fine-tuning is a continuous process.
After fine-tuning a model, you may want to align the model with human preferences. This is where alignment algorithms (DPO, KTO, IPO) and the Reinforcement Learning from Human Feedback (RLHF) technique come into play. We will discuss alignment in further detail in the next article of this series.
Players in the space
Many startups are making it easier for companies to fine-tune models. Players such as Weights and Biases excel in experimentation tracking, allowing users to log and track all aspects of their machine-learning experiments, including hyperparameters, code versions, datasets, metrics, model checkpoints, and more. They offer great visualization and dashboards, as well as collaboration and hyperparameter sweeps. Players like Databricks now offer easy-to-use APIs and tools for fine-tuning LMs, providing options for both high flexibility with popular frameworks and a simplified, fully-managed experience that handles resilient GPU training, default configurations, and data governance. Incumbents such as Google, through its Vertex Platform, offer a simple UI for fine-tuning and provide GPU access, creating an all-in-one solution. Others, such as Lamini, Anyscale, Together AI, Corewave, Lambda, and Foundry, provide the required GPU access and optimization engines for the fine-tuning process. Also, Open AI enables users to fine-tune some of its models through its platform.
Hugging Face, which plays a central role in the process, is worth highlighting separately. Hugging Face offers a comprehensive ecosystem for fine-tuning large language models, including dataset library integrations, a vast collection of pre-trained models, and the Model Hub for sharing fine-tuned models. Its transformer library and tools like the SFT trainer, ConstantLengthDataset for sequence packing, and PEFT library streamline the process and enable efficient training on various hardware setups. One interesting aspect about the leading players in the space is how partnerships are used to improve distribution. Hugging Face, for example, has integrations with platforms like W&B and recently announced its partnership with Google.
Other players like Predibase, offer solutions for both experienced and beginners in the fine-tuning journey. They provide an accessible, robust experience through a cost-effective managed service. Predibase’s platform provides built-in fine-tuning optimizations, recommendations for training settings, and templates for best practice techniques like LoRA — all through a user-friendly UI. For advanced users, Predibase offers a feature-rich SDK with options to fully customize training parameters like learning rate. Additionally, they have introduced innovations in model serving with the open-source release of LoRAX. Instead of requiring each fine-tuned adapter to replicate base model weights on its own GPU, LoRAX enables all adapters to share the same base model on a single GPU, significantly reducing inference costs. This allows for the efficient deployment of LLMs within the same infrastructure, with distinct requests allocated to different adapters through an intelligent scheduling system. Devvret Rishi, founder and CEO of Predibase, expands on the opportunity for fine-tuning:
“Increasingly, enterprises are realizing that bigger isn’t always better. With platforms like Predibase, developers can fine-tune smaller task-specific open-source models that outperform commercial LLMs at a fraction of the cost. To demonstrate this we recently launched LoRA Land, a collection of 25+ open-source adapters that rival GPT-4 all trained for less than $8 each on Predibase. Our goal is to show how any organization can efficiently and cost-effectively fine-tune their own LLMs without giving up model ownership or paying the high costs of serving commercial LLMs.”
One interesting aspect of fine-tuning is its applicability beyond text generation, extraction, or summarization. For example, refact.ai enables companies to fine-tune coding models specifically for their own code repositories. This is important because standard AI coding assistants provide generic solutions that may not align perfectly with specific project requirements or coding styles. While trained on vast datasets, they might not understand the nuances of every individual project. By fine-tuning the AI on a specific codebase, the model becomes more aligned with the project’s coding style, architecture, and dependencies, leading to more accurate and relevant suggestions (you can learn more about their approach here).
The Value and Future of Fine-Tuning: What this all mean for founder’s and executives
Fine-tuning offers companies a significant competitive advantage by enabling them to create proprietary AI models tailored to their specific needs. The fine-tuned models and the datasets used to train them can become valuable intellectual property (IP) for companies. This creates a barrier to entry for competitors, as replicating the fine-tuned model’s performance and knowledge would require significant time, effort, and data collection. By fine-tuning models on their unique datasets and for their specific use cases, companies can develop AI systems that are particularly adept at understanding the nuances, language patterns, and task requirements unique to their domain and customers. For example, a customer service company could fine-tune a language model to accurately capture the tone, terminology, and common issues specific to their business, enabling more effective and efficient support interactions.
In addition to its role in creating proprietary AI models, fine-tuning will also play a crucial role in the development of personalized AI agents. By tailoring the communication styles, tones, and formats of AI agents to specific user needs and contexts, companies can create more engaging and effective user experiences. For example, fine-tuned AI agents can be empathetic for healthcare or formal for business interactions. By training on curated datasets, these agents will excel at specific tasks and provide more natural, appropriate interactions. As AI becomes integral to everyday life, personalized fine-tuned models will significantly enhance user experiences across various domains, delivering cutting-edge, user-centric solutions that transform how we interact with technology. Etienne Bernard , founder of Numind, emphasizes the importance of fine-tuning in this context:
“Fine-tuning is the critical bridge between a generic AI model and a specialized agent adept at navigating the specific nuances of its operational context. By tailoring the model through iterative adjustments and data-informed alignment, we empower the agent to understand and interact with complex systems like APIs accurately, and adapt its behavior to meet user needs and expectations effectively”
While this article primarily focused on fine-tuning language models, it’s important to note that the benefits of fine-tuning extend to other domains, such as vision and audio models. For example, fine-tuning a pre-trained vision model on a dataset of medical images can improve its ability to detect specific diseases or abnormalities. As companies across various industries increasingly recognize the potential of fine-tuning to enhance the performance of AI models in specific tasks and domains, the relevance of fine-tuning vision models, especially in recognizing and classifying objects, scenes, or patterns specific to a particular task or domain, is expected to continue growing in the coming years.
In summary, fine-tuning is a technique that empowers AI models to excel at specific tasks and adapt to unique contexts. We are still very early in the adoption curve; most companies are in the process of setting up their RAG pipelines, and few have fine-tuned a model. However, as these methods continue to advance and become more accessible, we anticipate a surge in companies leveraging them to create powerful, specialized AI solutions.
As always, huge credit goes to my colleagues Chip Hazard and Jeff Bussgang for their feedback. I also want to express my massive thanks to Etienne at Numind and Michael Ortega from Predibase for their insights and quotes. At Flybridge, we are excited to back visionary founders and companies at the forefront of this AI revolution. If you are a founder building in this space or an operator who wants to exchange views, send me a message at daniel@flybridge.com. You can learn more about our AI thesis and history here.
Appendix A Common fine tuning techniques
Important Note: Instruction tuning is a powerful way to structure fine-tuning datasets. Rather than being a separate category, it can be used in conjunction with both full fine-tuning and parameter-efficient fine-tuning (PEFT) methods. By providing clear instructions and examples, you guide the model to learn how to follow your instructions and complete tasks effectively.
Full Fine tuning: Updating all parameters of a pre-trained model on a new dataset. Useful for task with sufficient, distinct data training
Parameter-Efficient Fine-Tuning (PEFT): Updating a small fraction of the model’s parameters, often with additional layers or reparameterization techniques. PEFT techniques have gained significant attention in the field of NLP as they enable the optimization of large language models for specific tasks without the need to train all the model’s parameters. These techniques are particularly useful when computational resources are limited or when fine-tuning needs to be performed quickly. PEFT methods allow for efficient adaptation of pre-trained models to various downstream tasks, making them more accessible and cost-effective.
For a deeper deep dive refer to this article Multitask Learning by Aman Chadha, that also include full list of LORA approaches. (Given medium limited features had to paste table in parts — For full table with links to the papers reffer to this link)